17 apr
grafikkort

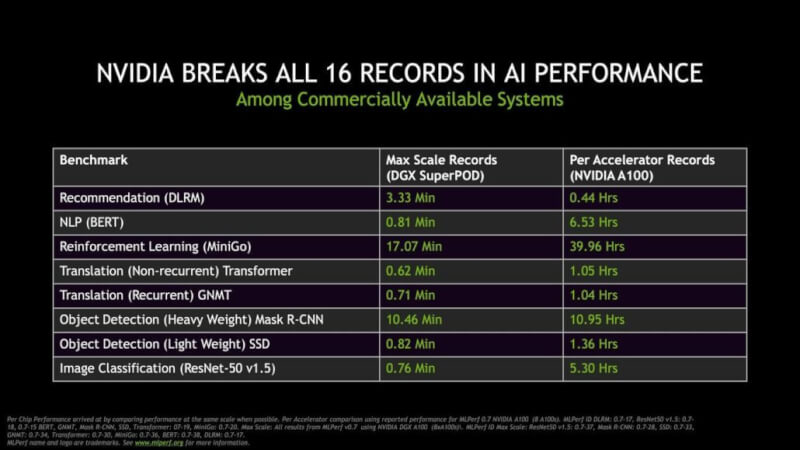
Resultaterne kommer fra MLPerf, som er en branchestandardgruppe, der blev dannet tilbage i 2018 med fokus på Machine Learning præstationer. Benchmarksuiten består af i alt otte test, og NVIDIA har indsendt resultater i alle med rekordtal.
“This is the third consecutive and strongest showing for NVIDIA in training tests from MLPerf, an industry benchmarking group formed in May 2018. NVIDIA set six records in the first MLPerf training benchmarks in December 2018 and eight in July 2019.
NVIDIA was the only company to field commercially available products for all the tests. Most other submissions used the preview category for products that may not be available for several months or the research category for products not expected to be available for some time.”
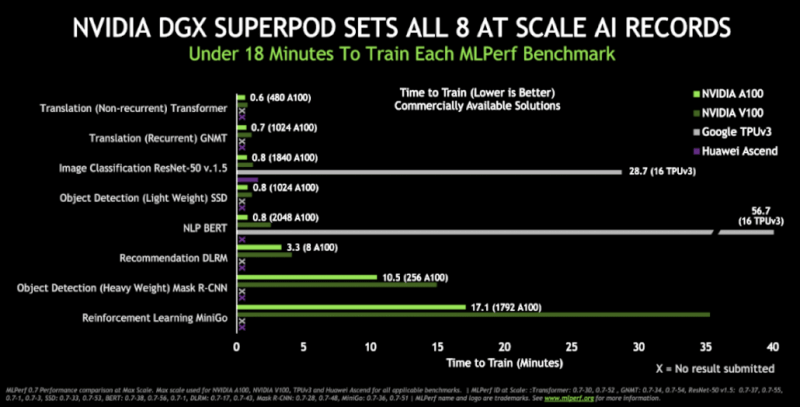
NVIDIA indrapporterede også otte yderligere poster med sit DGX SuperPOD system, som er en massiv klynge af DGX A100 HPC systemer, der er forbundet via HDR InfiniBand. DGX SuperPod består af 140 DGX A100 baserede systemer med i alt 1.120 NVIDIA Ampere A100 GPU'er, 170 Mellanox Quantum 200G Infiniband switche, 4 PB lagerplads og 15 km optisk kabel.
Source: Nvidia
Det er omkring 7,7 millioner Ampere CUDA cores inde i DGX SuperPod systemet….
Systemet er en del af DGX V udvidelsesplanen og tilføjer næsten 700 Petaflops computing performance til det system, der i øjeblikket er implementeret på NVIDIA’s hovedkvarter i Santa Clara, Californien.
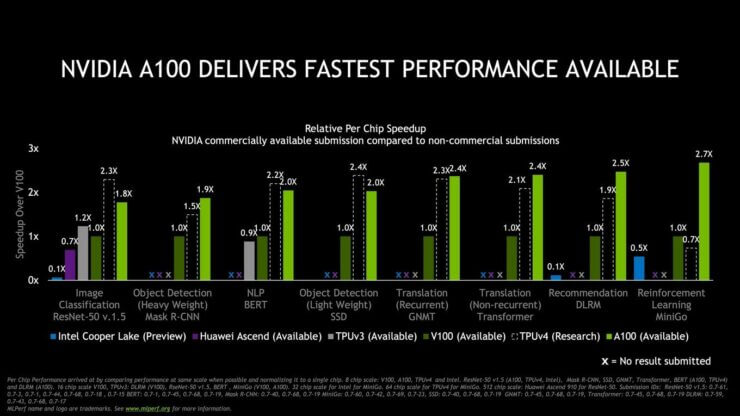
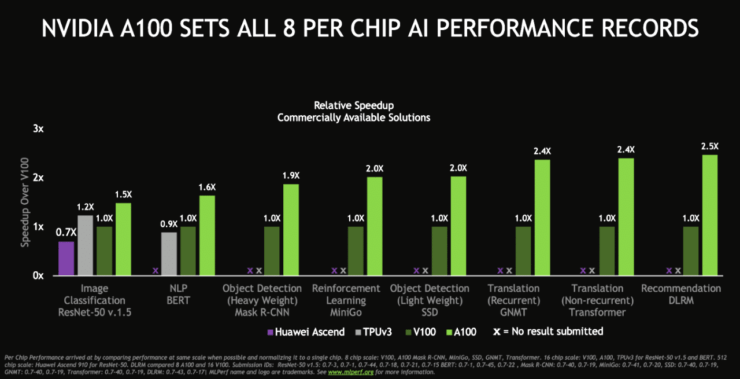
NVIDIA har sammenlignet deres Ampere A100 Tensor Core GPU accelerator med sin forgænger, Volta V100. Sammenligningen inkluderer også Googles 3. generation TPU og Huaweis Ascend HPC chips. MLPerf har selv mere detaljerede benchmarks listet og inkluderer også en forhåndsvisning af kommende AI-acceleratorer som Intels Cooper Lake-SP Xeon CPU'er og Googles 4. Gen TPU.
Med det sagt, lad os se på selve benchmarks.
Source: Nvidia
I henhold til MLPerf inkluderer deres benchmarksuite test, der er målrettet mod de arbejdsbelastninger, der er mest relevante inden for machine learning og AI-kategorier. NVIDIA Ampere A100 smadrer ifølge frigivne tal simpelthen Volta V100 med en ydelse, der øges med en faktor 2,5x. Selv med det mindste forspring leverer Ampere A100 et 50% løft over Volta V100, hvilket må siges at være imponerende. Chipskalaen her blev normaliseret til en enkelt GPU for at levere en retfærdig sammenligning mellem Ampere og Volta.
Source: Nvidia
Source: Nvidia
Huawei Ascend-chippen var i stand til kun at afslutte en test i tide og det også med dårligere ydeevne end Volta V100, mens Googles TPU V3 kun formåede at gennemføre to test i tide. I en test sikrede chippen 20% føring over NVIDIA Volta V100, mens den i den anden test var 10% langsommere end V100.
Sammenlignet med en Cooper Lake-SP 8-socket konfiguration, der afslutter billedklassificeringstesten på 1104,53 minutter, kan et dual NVIDIA A100 system gennemføre den samme test på kun 33,37 minutter. NVIDIA går også videre med at sammenligne ydelsen på sin Ampere A100 med den ikke-udgivne Google TPU V4, der stadig er i forskningsstadiet og mindst et år væk fra tilgængelighed.
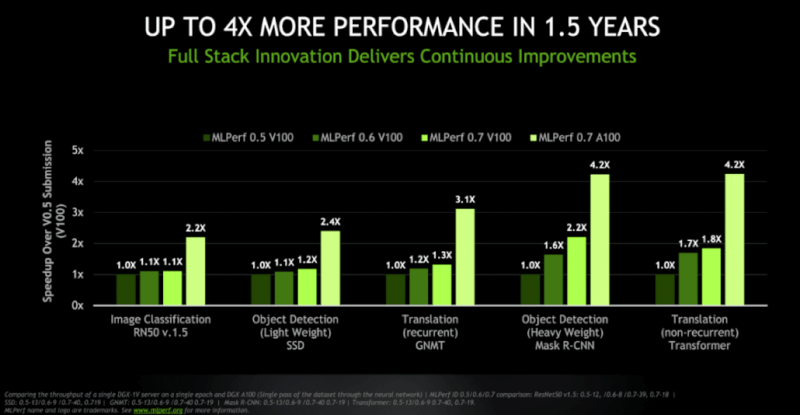
Source: Nvidia
NVIDIA viser også, hvordan ydelsen af deres GPU acceleratorer er forbedret over tid med de nyeste full-stack innovationer til AI. Sammenlignet med MLPerf 0.5, der kører på Volta V100, leverer MLPerf 0.7-pakken, der kører med Ampere A100, en forbløffende 4,2x ydeevne.
Dette viser, hvor imponerende NVIDIA Ampere A100 GPU er i real-world benchmarks inden for en pakke, der er anerkendt af alle større aktører i AI-segmentet. Ampere A100 GPU blev også betragtet som den hurtigste GPU, der nogensinde er udviklet.
Kom så med konsumer versionen!
Source & Image credit:
Nvidia




