22 apr
software

Siden OpenAI's ChatGPT sparkede den generative AI-boom i 2022, har det været klart, at det rette data, og nok af det, er essentielt for at skabe en AI-model, der er præcis, pålidelig og effektiv. Problemet? Det bedste data, især specialiseret "ekspert"data inden for specifikke områder som sundhed og finans, er sjældent.

AI-selskaber har gennemsøgt internettet for friske oplysninger, men AI-modeller er konstant sultne og skal fodres. Det San Francisco-baserede startup Gretel AI har længe troet på, at den mest tilfredsstillende løsning er at skabe kunstigt genereret data, der ligner karakteristika af virkelige data. Gretel hjælper klienter som EY, Google og det amerikanske justitsministerium med at generere syntetisk data, det vil sige, kunstigt genereret data, der efterligner egenskaberne af rigtige data.
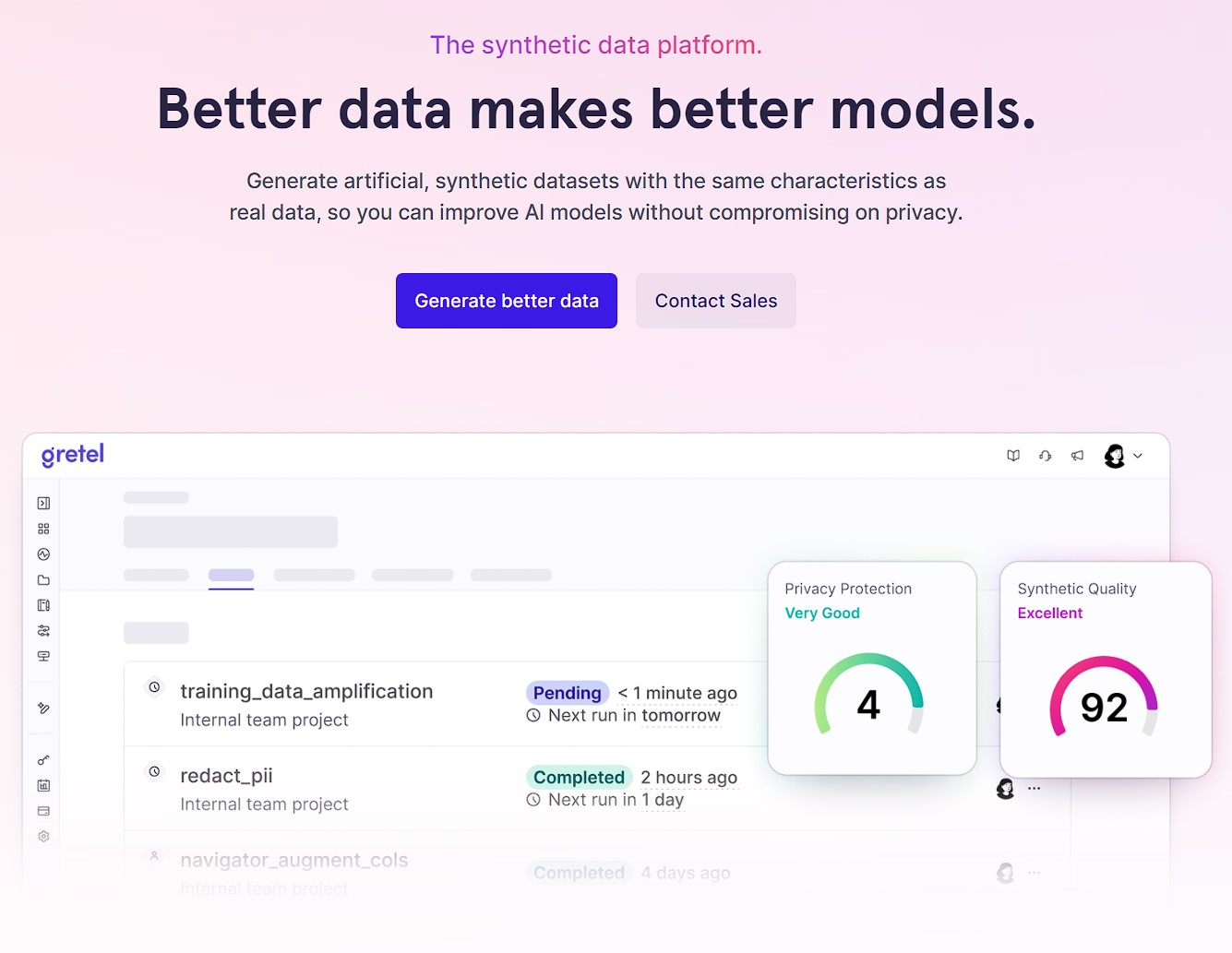
Og det bliver lettere at lave det: I dag annoncerede Gretel for eksempel den brede tilgængelighed af et generativt AI-drevet system, der lader brugere skabe syntetiske datasæt for tabulære data, tænk tekst- og taldata, der går i kolonner og rækker, som Excel-regneark, med bare en naturlig sprogkommando.
For eksempel, hvis en bank ønsker at skabe et syntetisk datasæt, der ligner deres egne kundedata, kan de bruge Greta's Navigator produkt til at skabe millioner af fiktive navne, ID'er, datoer, dollarbeløb og kontosaldoer. Det resulterende computer-genererede data krænker ikke kundeprivatlivet, da det ikke indeholder nogen reelle kundeoplysninger, og kan generere nok data til at træne en kraftfuld, præcis model.
I en æra med dataknaphed, hvor virksomheder er nødt til at søge andre kilder for at bygge generelle modeller eller finjustere specifikke opgaver, har syntetisk data et øjeblik i 2024, fortæller Gretel medstifter og CEO Ali Golshan til Fortune. Gretel's seneste produkt giver virksomheder mulighed for at generere data, selvom de mangler information.
Teknologien fokuserer på meget specifik data, der er beregnet til at forbedre individuelle opgaver inden for en klients interne systemer. Gretel er ikke alene om at forsøge at erobre markedet for generering af syntetisk data til AI-modeller. Startups som SynthLabs, Synthetaic og Clearbox AI kæmper alle om at levere virksomheder med alt det data, de har brug for, computer-genereret, selvfølgelig.
Gretel's næste store skridt er at bygge en syntetisk data- og modeludveksling, der vil tage virksomheden til det næste niveau og gøre dem til den sikre grænseflade for privat data. Data er drivkraften bag AI. Og Gretel AI er bestemt på vej mod at blive en af de mest innovative spillere på dette område.
Dette har ført Golshan og hans medstiftere til at overveje fremtiden. Han siger, at virksomheder snart vil kunne tjene penge ved at tillade andre at købe syntetiske data, der er trænet på organisationens unikke datasæt. Organisationer, der har masser af data, men ikke bygger AI-modeller, kunne for eksempel sælge andre adgang til deres data for at hjælpe med træningen af deres syntetiske data.
Med dette for øje, sagde Golshan, at Gretel's næste store skridt er at bygge en udveksling af syntetiske data og modeller. "Vi vil gøre det muligt for virksomheder og kunder at træne modeller på deres data, få matematiske garantier for, at dataene er sikre, og nogen kan komme og 'abonnere' på den model, generere data og betale efter forbrug," forklarede han.
Dette, tilføjede han, vil tage Gretel til det næste niveau for at "blive det sikre interface for private data, hvor man fjerner denne udnyttende tilgang til minedrift og høstning af data." Det ville også betyde, at virksomheder som Anthropic og OpenAI, som har bygget enorme AI-modeller baseret på massive mængder data, ikke skulle indgå licensaftaler med hver enkelt virksomhed, de ønsker at få data fra, sagde han.
Hvad angår finansiering, har Gretel rejst i alt 68 millioner amerikanske dollars med deres Series B tilbage i 2021. Golshan sagde, at startup-virksomheden har mange penge tilbage, med "omkring to års drift foran os." Men i dette "øjeblik" for syntetiske data, siger han, at han ser en mulighed for at bygge den næste Databricks eller Snowflake, to af de største data-cloud platforme, eller endda OpenAI.
"Vi går ret aggressivt ind i det, fordi vi har en stor tiltrækning," sagde han. "Vi forestiller os at bygge den næste sikre, høj-kvalitets databusiness, hvilket, hvis du tænker på behovene, er en ret betydelig mulighed."




