13 aug
grafikkort

Kampen om fodfæste på markedet for AI chips spider til og senest har både Nvidia og AMD være efter hinanden i forhold til deres nyeste AI rettede GPU ships.
Senest blev slaget udspillet ved AMDs Advancing AI-event, hvor de afslørede deres seneste kraftcenter, MI300X. Lisa Su, AMD's administrerende direktør, og hendes team præsenterede MI300X ved at udfordre NVIDIA's H100. De hævdede, at en enkelt AMD-server med otte MI300X-enheder oversteg en H100-server med 1,6 gange hastigheden, og dermed demonstrerede overlegenheden af deres seneste produkt.
Dog accepterede NVIDIA ikke AMD's præstationsmålinger og modsagde dem hurtigt. I en blogpost argumenterede NVIDIA for, at deres H100 GPU, når den blev benchmarket korrekt med optimeret software, oversteg AMD's MI300X betydeligt. De påstod, at AMD ignorerede de optimeringer, NVIDIA's TensorRT-LLM tilbyder, i deres sammenligning.
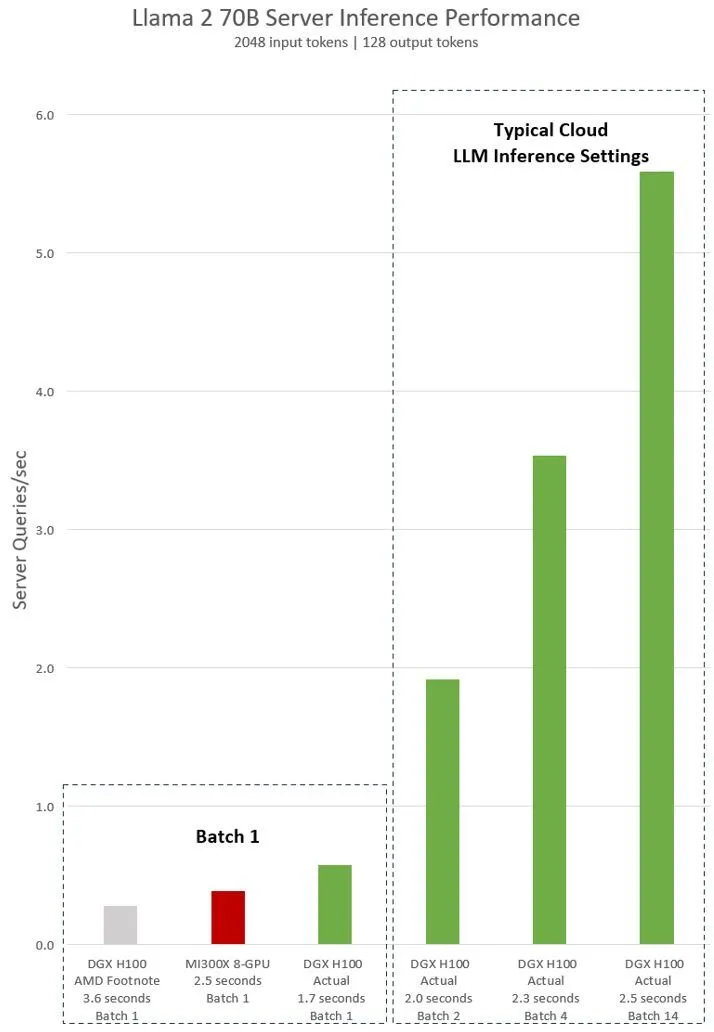
NVIDIA satte en enkelt H100 op mod otte H100 GPU'er ved brug af Llama 2 70B chatmodellen. Resultaterne, opnået med software, der forudgik AMD's præsentation, viste, at H100 var dobbelt så hurtig ved en batch-størrelse på 1. Desuden hævdede NVIDIA, med anvendelse af AMD's standard 2,5-sekunders latenstid, at de var klare vindere og overgik MI300X med imponerende 14 gange.

AMD veg dog ikke tilbage fra NVIDIAs udfordring. De reagerede med nye MI300X benchmarkresultater, der indikerede en 30% præstationsforbedring over H100, selv med perfekt tilpasset software. I et forsøg på at replikere NVIDIAs testbetingelser med TensorRT-LLM overvejede AMD strategisk latency, en almindelig variabel i serverbelastninger.
De fremhævede fordelene ved at bruge vLLM med FP16 over TensorRT-LLM's FP8, en fordel eksklusivt tilgængelig for AMD. AMD anklagede også NVIDIA for at bruge deres proprietære TensorRT-LLM på H100 til benchmarks i stedet for den almindeligt anvendte vLLM. De påpegede også inkonsekvensen i datatypens brug, idet NVIDIA brugte vLLM FP16 på AMD, mens de sammenlignede det med DGX-H100's TensorRT-LLM med FP8-datatype.
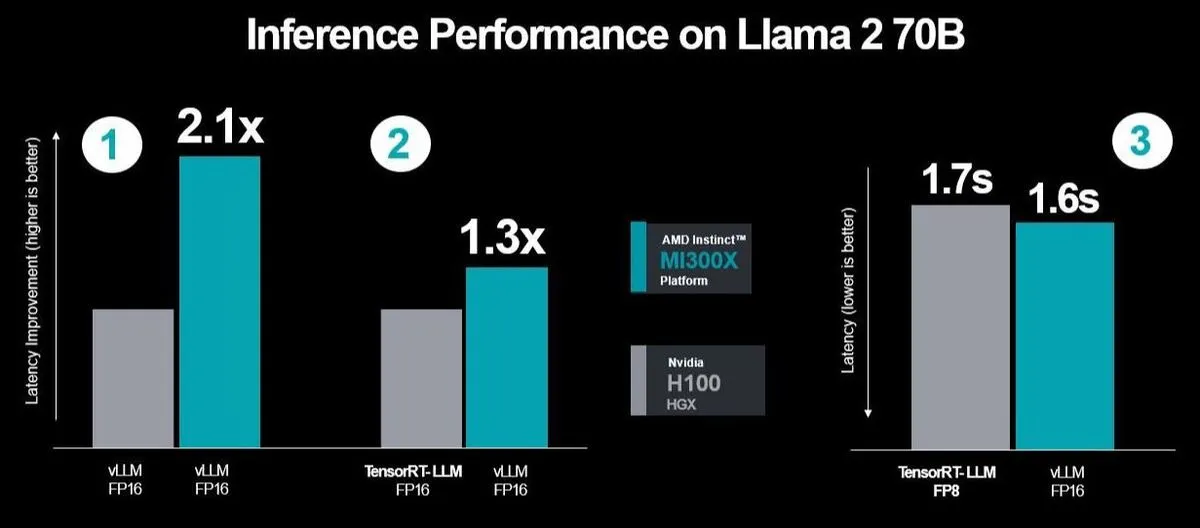
AMD forsvarede deres valg af vLLM med FP16 og argumenterede for dets brede anvendelse, i modsætning til vLLM, som ikke understøtter FP8. AMD stillede også spørgsmålstegn ved NVIDIAs fokus på throughput-præstationer og kritiserede dem for at ignorere latency-problemer i virkelige servermiljøer. For at udfordre NVIDIAs testmetodologi udførte AMD tre ydelsesløb ved hjælp af NVIDIAs TensorRT-LLM. Det sidste løb målte specifikt latency mellem MI300X og vLLM ved hjælp af FP16-datasettet over for H100 med TensorRT-LLM.
Resultaterne viste forbedret ydelse og reduceret latency, og yderligere optimeringer førte til en 2,1 gange ydelsesforøgelse sammenlignet med H100, når vLLM kørte på begge platforme. Denne vedvarende konkurrence mellem NVIDIA og AMD har været en langvarig rivalisering, men det er første gang, NVIDIA direkte har sammenlignet præstationen af deres produkter med AMD's, hvilket signalerer en intensivering af konkurrencen i tech-sektoren.

Med disse påstande og modpåstande er rampelyset nu på NVIDIA for at svare på AMD's påstande. De skal overveje de potentielle konsekvenser af at opgive FP16 til fordel for TensorRT-LLM's lukkede system med FP8. Samtidig skal de også være opmærksomme på andre konkurrenter som Intel og Cerebras, der bliver stadig dygtigere til at skabe GPU'er. Tech-markedet er ikke kun et væddeløb med to spillere fordelt mellem NVIDIA og AMD. Andre virksomheder som Cerebras Systems og Intel sigter også mod at efterlade deres aftryk. Intels administrerende direktør, Pat Gelsinger, teasede for nylig Gaudi3
Kilde: analyticsindiamag.com




